
Efficient Deep Learning
Published:
Making Deep Learning Efficient
Why do we care about hardware when it comes to deep learning ? There are a number of practical reasons to warrant more efficient DL systems:
- Lower power consumption: This has an impact on range for applications like self-driving cars.
- Lower latency: Anything is fast is welcome. Models whose weights can be saved on fast on-chip memory/registers have fast inference as on-chip memory has the lowest access time.
- Saved real estate from no heat sink requirement: The ability to run on more compact hardware enables deployment of ML systems on UAVs, smartphones etc. Usually models requiring frequent memory accesses run hotter.
- Smaller download size for OTA update: Software updates for ML applications can be less bulky and have more penetration.
- Ability to run on cheaper hardware: A no brainer, this is always good to have for wide adoption.
The Hardware Angle
So why does specialised hardware work so well ? A number of reasons,
ML specific hardware can have improvements such as higher on-chip memory (like register memory on GPUs) to be able to store weights etc. This reduces the need for expensive accesses to off-chip memory (global memory) and improves throughput and reduces latency.
In deep learning applications, memory bandwidth is constrained due to constant reloading of the next layer, storing activations in global memory and performing the next set computations. Better hardware (than general purpose GPUs) can alleviate this. If activations can also be stored in on-chip memory (alongwith weights), its even better !.
Purpose-built custom hardware provides extensive performance improvements and speedups owing to the the fact that most of deep learning inference and training is just matrix multiplications. It holds especially true for CNNs.
Hardware like TPUs are ASICs built for matrix multiplication only and bypass the von Neumann bottleneck. For example, they might perform 64x64 matrix multiplications in a single pass with memory access required only once.
 An example of a case where some primitive tensor ops (kernels) can be fused to avoid the need to store intermediate results. Source: https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html
An example of a case where some primitive tensor ops (kernels) can be fused to avoid the need to store intermediate results. Source: https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html
- Hardware like TPUs also support specialised compilation like XLA. XLA fuses multiple CUDA kernel ops depending upon the program and runs them at once, instead of each kernel being called separately. (See here). Such fused implementations minimize global memory accesses thus saving precious memory bandwidth. This also reduces overhead associated with multiple kernel launches.
The Model Architecture Angle
When your architecture is yet to be defined
Apart from having custom hardware, a lot of research has gone into optimizing neural network architectures that make them suited for hardware deployment.
Some of the tricks frequently used include,
Fully connected layers are substituted with 1x1 convolutions owing to memory considerations. Convolutions are much more light due to weight sharing while fully connected layers with n inputs and m outputs have a quadratic (O(nm)) memory requirement !
SVD decomposition of fully connected layers is also used to lower both the number of parameters and inference time.
In a similar spirit, low-rank matrix factorization of larger convolutional kernels reduces them into 2 smaller unidimensional kernels. This again reduces number of trainable parameters and inference time.
Bottleneck filters like 1x1 kernels are used to reduce number of channels and thus reduce computational load for successive kernels.
In architectures like MobileNet V2, this trick is also used to keep the number of channels fixed throughout to keep the tensor (flowing through the net) size manageable.
Reversible Networks, an Uber AI creation reduces memory requirement by not caching intermediate activations. The layers are interspersed with reversible layers that recompute those activations when the gradients flow through them during the backward pass.
Of course, autoregressive models are growing out of favour with the rise of parallelized sequence models like Temporal Convolutions and Self/Relative Attention. The latter even generates some great music ! Check it out
When your architecture is already defined
When a model architecture is already given, the Deep Compression paper by Han et al provides the following techniques to help in compressing models further.
Pruning of low magnitude weights helps in keeping things sparse, thus reducing computational load and reducing memory footprint.
K-means clustering of weights reduces the number of unique weights. Given a set memory budget (and thus a defined ceiling of number of bits used to represent each weight), the clustered weights can be quantized to further reduce memory footprint.
Quantized (clustered) weights, due to their lower memory requirement, can be fit onto fast on-chip memory and thus also speed up inference.
Moreover quantization into integers also speeds up things due to the fact that integer arithmetic is usually faster than floating point arithmetic on computers.
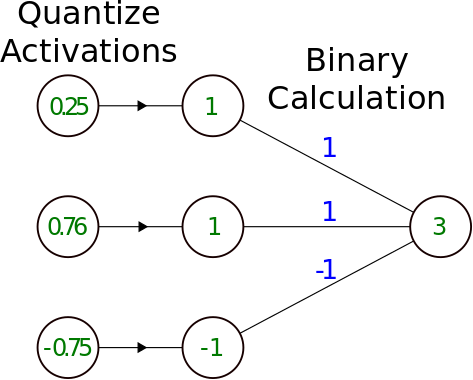
An example of binary quantization. The binary operation in this case is a convolution with kernel [1 1 -1]. Source: https://medium.com/@joel_34050/quantization-in-deep-learning-478417eab72b
Note about quantization: When both weights and activations are quantized, one must ensure that the input distribution to a quantized layer must be similar to the output distribution, for quantization and dequantization to be effective. This is why ReLU is never quantized by itself but clubbed with an adjacent layer to keep input and output distributions of the combineed unit similar.
- In order to store the model with even lower memory, Huffman Coding is used to reduce the bit representations of more common weights (bigger cluster) to fewer bits.