
Leveraging Eye Gaze to Enhance Imitation Learning
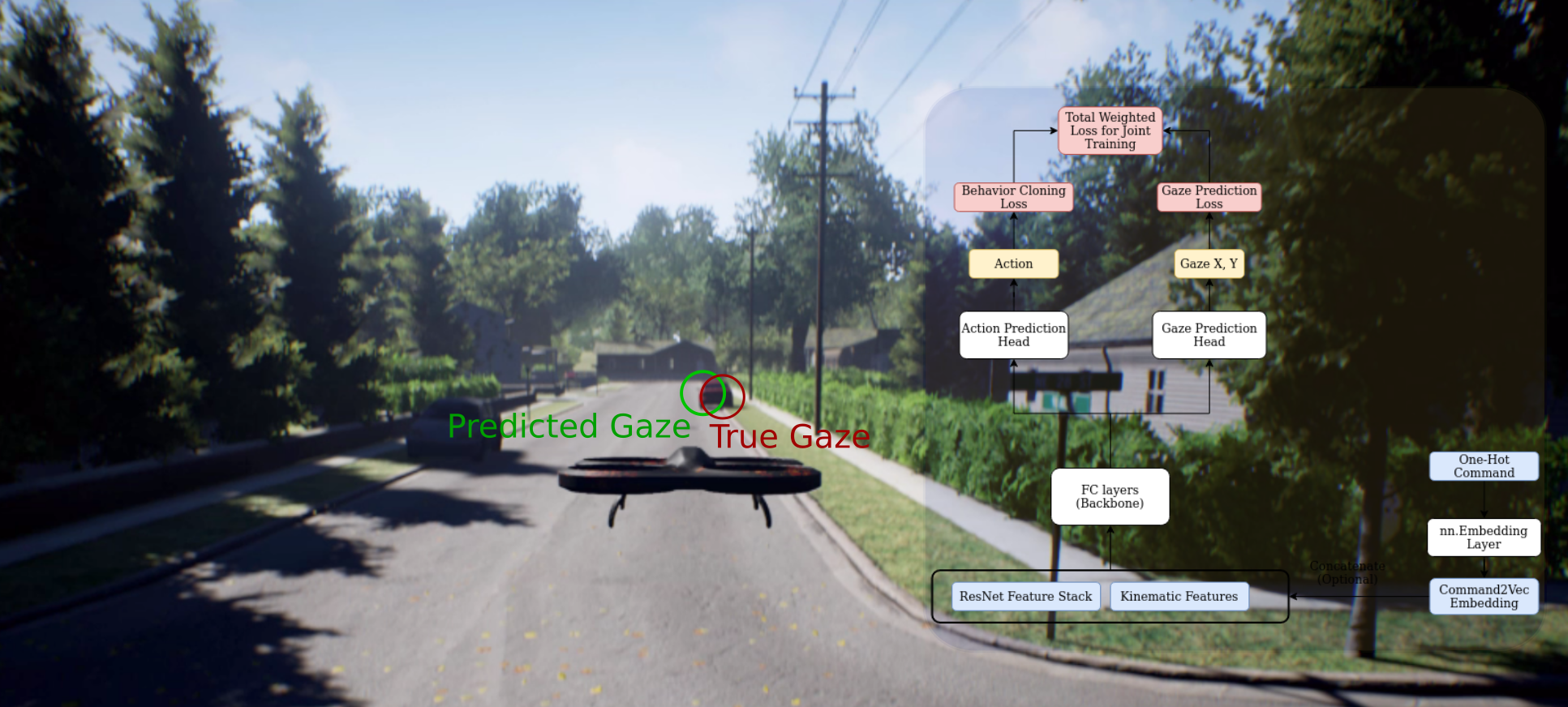
Overview
In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation.
However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context.
The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a photorealistic cluttered forest environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient routing.
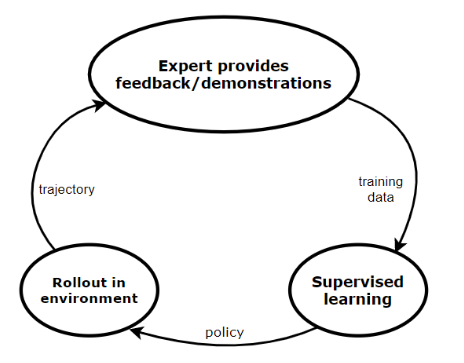
Figure: Training robots to do tasks in the physical space via a dataset of human demonstrations follows the same prinicples as any other supervised ML problem with a custom evaluation component. Interventions during rollouts act as a error-guided feedback-driven data engine.

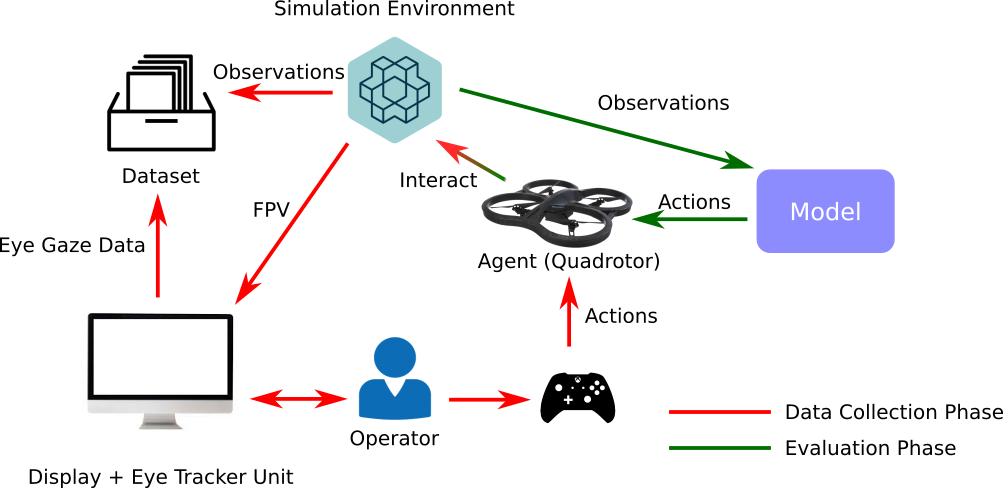
Figure: Block diagram of the proposed multi-objective learning architecture to learn from multimodal signals from human demonstrations, in this case, from both actions and eye gaze data.

Video 1: A comparison between a policy trained with gaze against one trained without gaze. Notice that the Vanilla BC model loses track of the target truck even when it was in its field of view, while the Gaze BC model successfully completes the task
Approach
Designing the Model
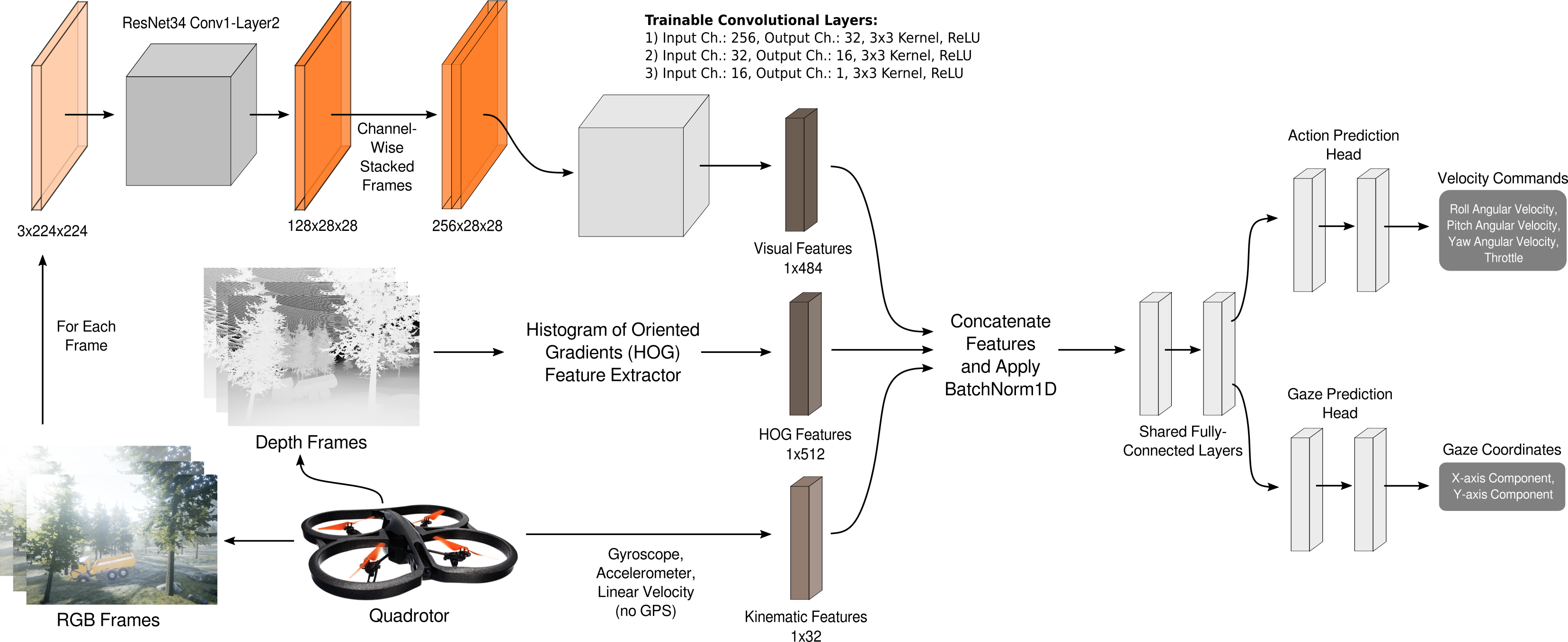
Figure: The proposed model architecture illustrating how quadrotor onboard sensor data and cameras frames are processed, how features are combined in a shared representation backbone, and how multiple outputs, i.e. the gaze and action prediction networks, are performed via independent model heads.
Ensuring Performance on Hardware
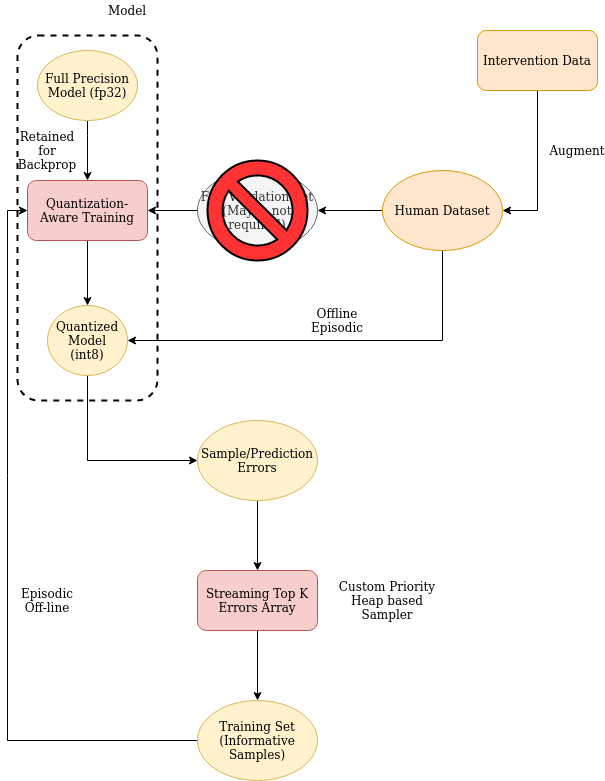
Figure: System diagram showcasing resource-efficient implementation on hardware
Highlights and Learnings
- Continuous Improvement: As a big believer in the importance of data quality as the primary driver in improving model performance, a big focus in this project was to come up with a evidence-guided data augmentation process. This is more so because collecting data for robotics related tasks (expert demonstrations) is expensive in terms of time and effort.

Figure: A custom tool built using matplotlib to help mine max error datapoints from the rollout trajectories. This helps in revealing gaps in the model’s understanding and guides the next round of data collection for continual improvement.
Modular Programming: The entire codebase was meticulously designed to follow a plug-n-play architecture which makes rapid iteration so much better. Be it data samplers, feature generator functions or model architectures, everything is hot-swappable.
Continuous Integration: The codebase was designed to allow for a one-click training and evaluation process. Multiple models get trained, hundreds of trajectory rollouts happen in an Unreal Engine-backed simulator, and multiple metrics get evaluated with just one-click. This is very helpful for CI processes in a reasonably complex ML projects like this.
Technology Stack
Some core components that I found immensely helpful in this project,
MLFlow: Experiment tracking was critical for rapid iteration and answering ‘What caused that to change ?’ style questions. Pretty indispensable in making the correct judgement calls.
- Git & DVC: Version of the dataset and not just code is something that I didn’t realize was so essential before. Data versioning is critical especially since more/better data usually trumps any model architecture hacks/tricks in improving performance.
Sidenote: DVC generated metadata files of the dataset (.dvc) that are in turned versioned using git. Since git commit hashes are logged in MLFlow, it is even possible to know what training data was used for a specific experimental run. Pretty nifty stuff.
PostgreSQL: Having an SQL-based backend for storing experimental data is better simply because there are still a number of types of queries that MLFlow still can’t quite handle.
- Docker: Continuous Deployment supported by version controlling the project’s Docker image via Docker Hub. In my opinion, Docker is a no-brainer solution when it comes to ensuring portability and reproducibility for ML projects.

Figure: Development tools used in this project